



여기서 다루는 내용
· 서비스 간단 소개
· 구성
· Kinesis data streams 생성 및 데이터 전송
· EMR(hive) 생성 및 Kinesis data streams 쿼리
· Checkpoint 기능 적용
· 마무리
아직 서울 리전에서는 kinesis analytics가 지원 되지 않고 있어서(2018.04 기준) Kinesis data streams을 쿼리 하려면 별도의 개발이 필요한데요.
EMR의 hive를 활용하여 실시간으로 수집되는 kinesis 데이터 스트림을 쿼리하는 작업을 해보겠습니다.
추가적으로 EMR의 hive metastore를 외부로 분리도 해보며 hive 어플리케이션 구성 변경과 bootstrap action 적용도 같이 해보도록 하겠습니다.
※ EMR release 5.12.1 기준 작성 (2018.04 기준)
서비스 간단 소개
- EMR(Elastic Map Reduce)
- 관리형 하둡 서비스
- Apache Spark, HBase, Presto, Hive와 같이 널리 사용되는 분산 프레임워크를 실행
- Amazon S3 및Amazon DynamoDB와 같은 다른 AWS 데이터 스토어의 데이터와 상호 작용
- 수동 또는 Auto Scaling을 통한 인스턴스 수를 늘리거나 줄일 수 있으며, spot 인스턴스 활용을 통한 비용 절감 가능
- 제품 세부 정보 : Link
- Kinesis data streams
- 완전 관리 서비스
- 탄력적인 트래픽 대응
- 리전의 여러 가용 영역에 기본 24시간 저장되며 최대 7일 까지의 안전한 데이터 보관
- Real-Time Streaming Processing
- 제품 세부 정보 : Link
구성
Kinesis stream에 데이터를 전송하고, 이 데이터를 hive 클러스터에서 바로 Ad-hoc 쿼리 분석 가능하도록 구성합니다.
추가적으로 hive metastore를 외부로 분리하고, DynamoDB에 kinesis checkpoint를 분리하는 부분도 추가해 보도록 하겠습니다.

① Kinesis 데이터 스트림을 생성하고 스트림 데이터를 전송 합니다.
② EMR 클러스터 생성 및 연동을 하고, 생성시 Hive metastore를 분리합니다.
③ Kinesis Checkpoint table 을 활용하여 특정 시점까지의 데이터를 조회하여 결과를 확인합니다.
Kinesis data streams 생성 및 데이터 전송
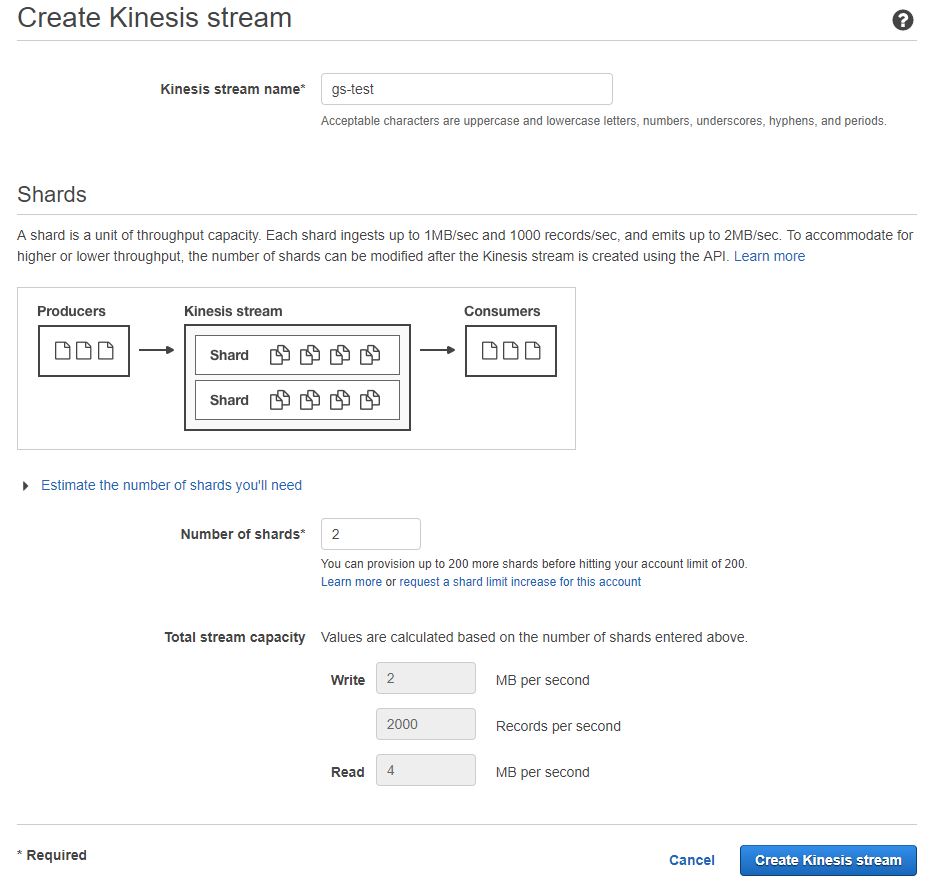
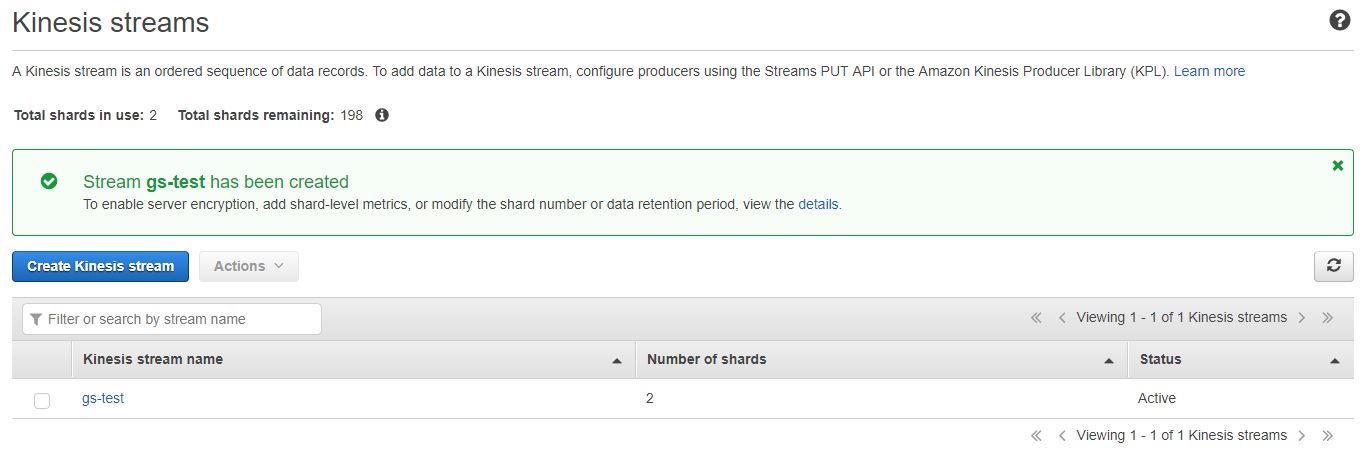
:: Kinesis 생성
먼저 kinesis data stream을 생성합니다.
:: 데이터 스트림 전송 준비
Kinesis data stream에 데이터를 지속적으로 넣어주기 위해 아마존에서 샘플로 제공하는 amazon-kinesis-learning 소스를 다운로드하여 스트림 데이터를 생성하여 전송하도록 쉽게 변경 가능합니다.
먼저 코드를 다운로드하여 import하고, StockTradeWriter 에서 전송되는 데이터를 ',' 구분자로 구분되도록 변경합니다.
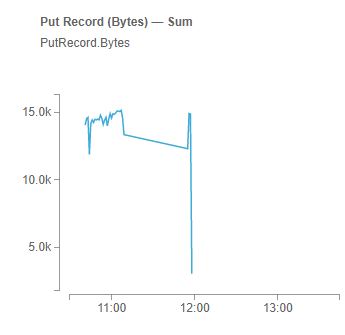
:: 데이터 스트림 전송 및 적재 확인
StockTradeWriter class의 main 메소드를 실행시키고, 실제 Kinesis에 데이터 스트림이 적재되는 것을 모니터링 화면에서 확인 가능합니다.
EMR(hive) 생성 및 Kinesis data streams 쿼리
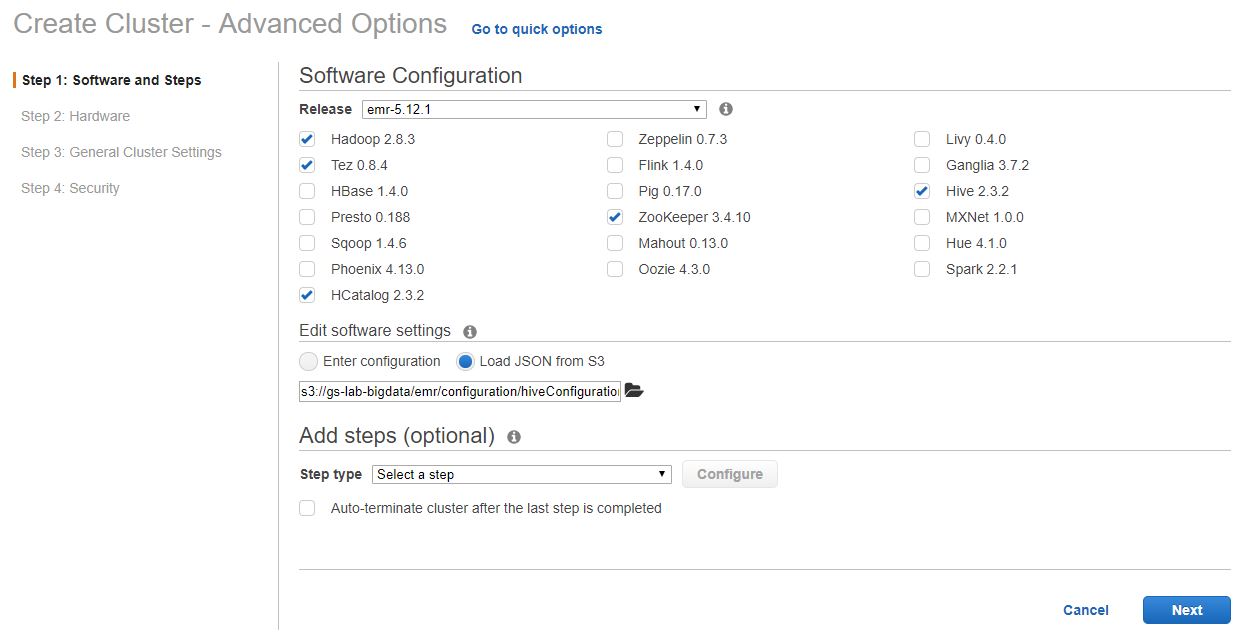
:: HiveMetastore 설정
아직 서울 리전에는 AWS Glue Data Catalog 가 지원되지 않기 때문에 안정적으로 Hive Metastore를 운영하려면 외부에 별도의 RDBMS를 생성하여 관리 할 수 있습니다.
아래 이미지와 같이 configuration 설정을 추가하여 hive-site.xml 파일의 hive metastore를 바라보는 설정 값을 변경합니다. 참고로 어플리케이션 구성 설정을 변경하는 부분은 여기서 확인 가능합니다.

※ 참고
위에서 미리 생성한 RDBMS metastore 설정으로 configuration을 적용하면 hive 2.3.0 이상 버전에서 아래와 같은 오류로 생성이 실패 되는 경우가 있습니다. (주의 : 2018.04 기준)

이런 경우 metastore의 schema 버전을 업그레이드 해줘야 합니다. schematool을 사용하여 schema 버전을 업그레이드 합니다. schematool 관련한 내용은 여기 참고 바랍니다.
아래와 같이 bootstrap actions 을 활용하여 클러스터 생성시 자동으로 업그레이드 되도록 합니다.
bootstrap actions :
#!/bin/sh
sudo /usr/lib/hive/bin/schematool -upgradeSchema -dbType mysql
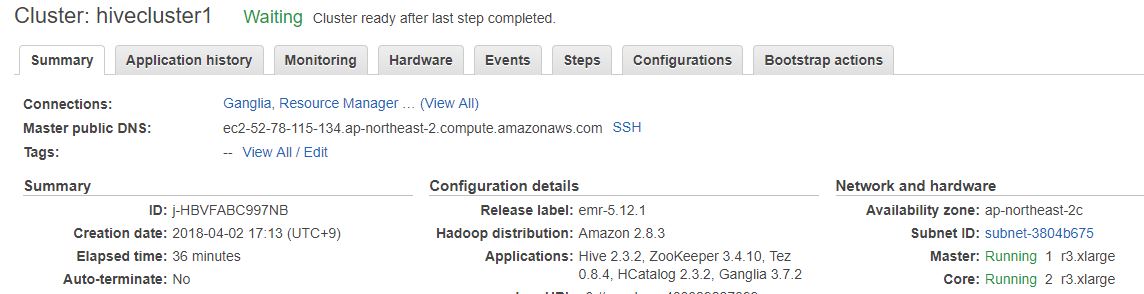
정상적으로 생성이 되면 아래와 같이 Waiting 상태가 됩니다.
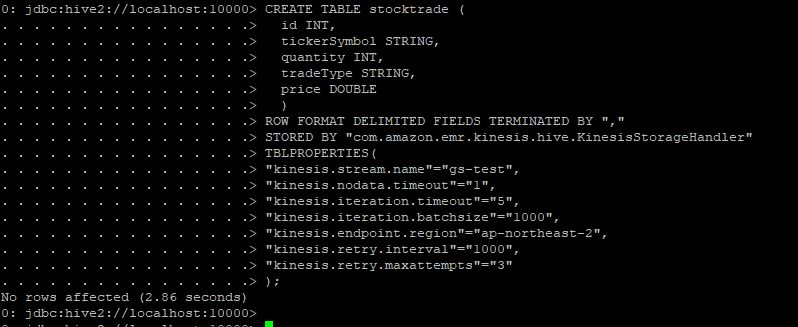
:: Hive DDL 실행 및 데이터 확인
hive에 접속하여 구분자를 "," 로 설정하여 kinesis와 통합되도록 테이블을 생성합니다.
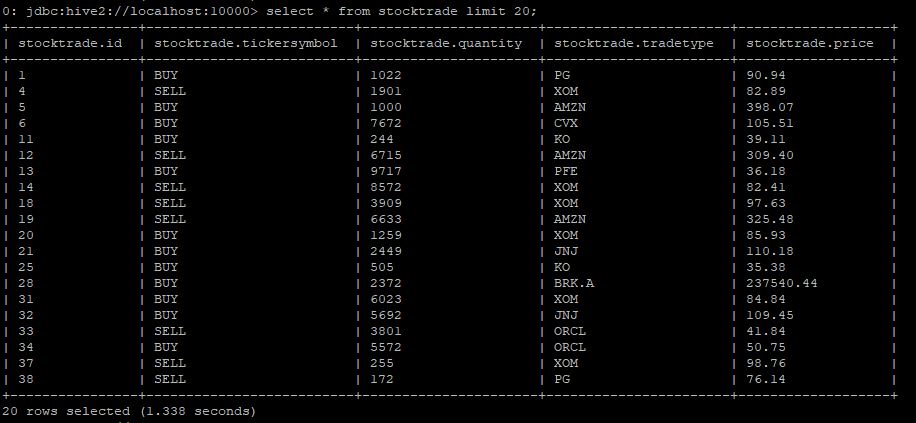
kinesis로부터 데이터를 정상적으로 읽는지 간단 확인해보면 데이터가 정상적으로 잘 나옵니다.
Checkpoint 기능 적용
EMR은 Kinesis 입력 커넥터를 통해 프로세스에서 반복이 가능합니다. 즉, 예약된 주기적 작업을 할 수 있도록 지원합니다.
이를 활용하기 위해서는 DynamoDB 테이블이 필요합니다.
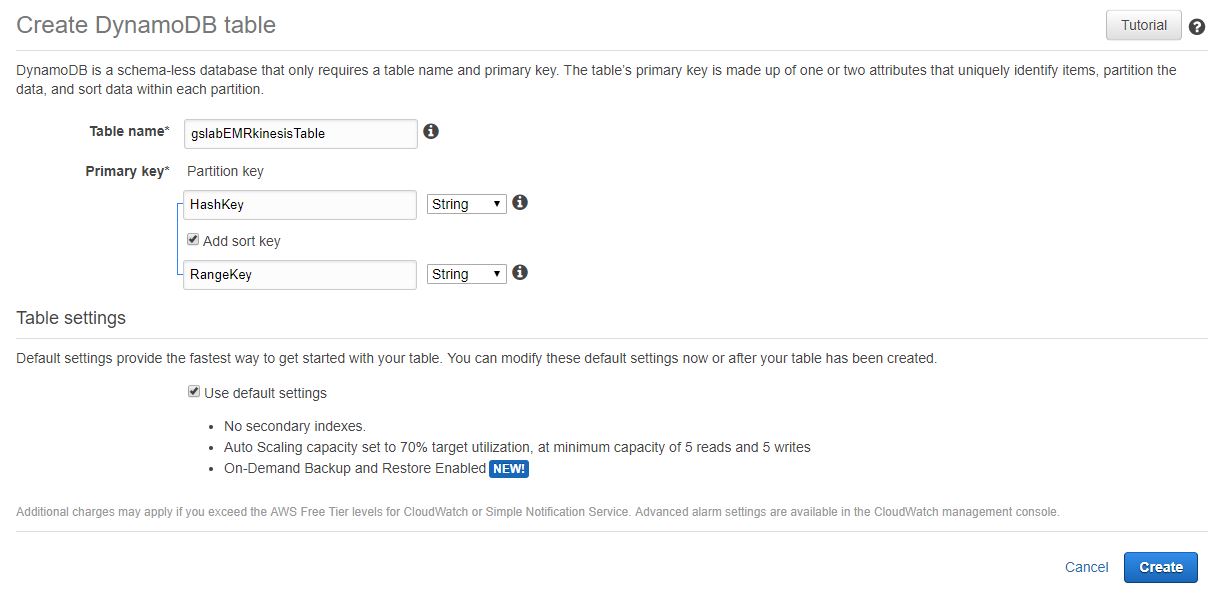
:: DynamoDB 생성
kinesis의 checkpoint로 사용하기 위해 HashKey와 RangeKey를 Primary Key로 생성합니다.
자세한 내용은 여기에서 Amazon Kinesis 스트림의 검사 분석 부분 확인하시면 됩니다.

:: checkpoint 설정
hive에서 아래와 같이 구성 파라미터를 설정합니다.
set kinesis.checkpoint.enabled=true; <- 활성화
set kinesis.checkpoint.metastore.table.name=gslabEMRkinesisTable; <- DynamoDB 테이블 이름
set kinesis.checkpoint.metastore.hash.key.name=HashKey; <- DynamoDB 테이블의 해시 키 이름
set kinesis.checkpoint.metastore.range.key.name=RangeKey; <- DynamoDB 테이블의 범위 키 이름
set kinesis.checkpoint.logical.name=TestLogicalName; <- 현재 처리의 논리적 이름
set kinesis.checkpoint.iteration.no=0; <- 논리적 이름과 연관된 처리의 반복 번호
kinesis stream에 전송하는 작업을 종료하고, hive 쿼리로 테이블 전체를 count를 해보니 16361 건이 확인됩니다.
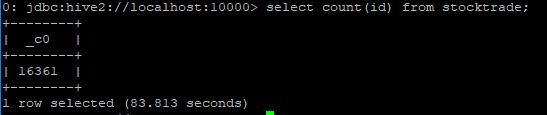
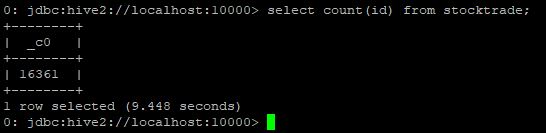
다시 kinesis stream에 전송하는 작업을 시작합니다. 도중에 다시 count를 해보면 위의 결과와 동일한 같은 값이 나오는 부분이 확인 됩니다.
dynamoDB에 저장된 checkpoint를 활용하기 때문입니다.
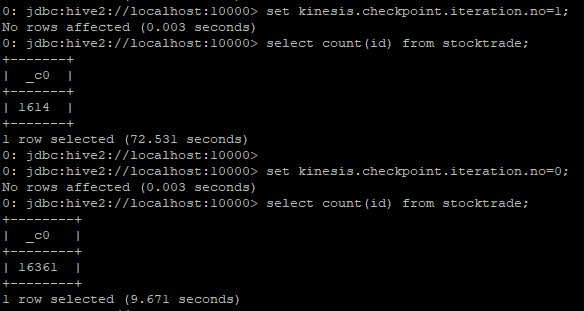
그럼 kinesis stream에 전송하는 작업을 종료하고 kinesis.checkpoint.iteration.no 값을 1로 설정하고 count를 해보겠습니다. 1614건이 확인되고,
다시 kinesis.checkpoint.iteration.no 값을 0으로 설정하고 count를 하면 16361건이 확인 됩니다.
마무리
EMR에서 hive를 활용하여 kinesis에 실시간으로 적재되는 데이터를 쿼리하고, checkpoint를 적용하여 특정 시점의 데이터를 확인해 보았습니다.
이상 EMR의 hive로 kinesis 데이터 스트림을 분석하는 시간을 마무리합니다.