



Reinvent2017 주요 업데이트 - 데이터 분석 분야 Summery
· Amazon S3
· Amazon Glacier
Amazon S3는 AWS 빅데이터 분석 서비스의 기본 저장소로서 대부분의 데이터 분석은 객체 단위로 이루어지며 Data Lake 역할을 수행하는데 적합한 서비스입니다.
이번 ReInvent 2017에서 손쉽게 S3 및 Glacier 저장소의 데이터를 쿼리 할 수 있도록 select를 제공하여 Data Lake의 성능을 강화해 줄 것 같습니다.
Amazon S3
S3 Select (Preview)
1) 주요 특징
- 단순한 SQL 표현식을 사용하여 해당 객체에서 필요한 바이트만 추출 가능.
- 응용 프로그램이 간단한 SQL 표현식을 사용하여 객체에서 데이터의 하위 집합만 검색할 수있음 -> 데이터의 양을 줄임으로써 응용 프로그램의 성능 향상.
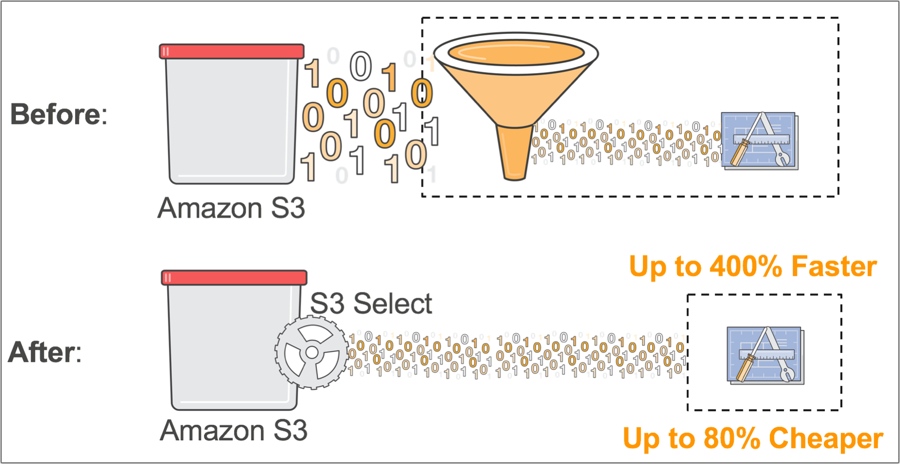
- AWS Lambda 로 구축 된 Serverless 응용 프로그램에 유용.
- Amazon EMR 에 대한 Presto 커넥터를 만들었음. (Presto 커넥터는 S3에서 검색된 데이터의 거의 99 %를 필터링 한 복잡한 쿼리를 실행)
- Amazon Athena , Amazon Redshift 및 Amazon EMR 은 물론 Cloudera, DataBricks 및 Hortonworks와 같은 파트너 모두 S3 Select 지원 예정.
- (Preview ) GZIP 압축을 사용하거나 사용하지 않고 CSV 또는 JSON 파일 지원.
- (Preview) S3 Select에 대한 요금은 부과되지 않음.
Amazon Glacier
Glacier Select (Preview)
1) 주요 특징
- 모든 상업적인 리전에서 수행가능.
- 표준 SQL 문을 사용하여 Glacier 객체에 대해 직접 필터링 수행. (Cold data를 빠르게 검색)
- 018 년에 Athena가 Glacier Select를 사용하여 Glacier와 통합될 예정임.
2) 요금
- 아래 3가지 요인에 따라 비용 책정
- GB of Data Scanned
- GB of Data Returned
- Select Requests
- 각 측정 기준의 비용은 아래 결과의 속도에 따라 결정됨
- expedited (1 ~ 5 분)
- standard (3 ~ 5 시간)
- bulk (5 ~ 12 시간)
자세한 내용은 여기 참고 바랍니다.