AWS EMR Series - Hive geospatial 데이터 조회
Jan 18,2019 | AWS
작성자_김명수



문의 주신 내용에 맞는 전문 컨설턴트 배정 후 연락드리겠습니다.
Jan 18,2019 | AWS
작성자_김명수

· 간단 소개
· 사전 준비
· Hive UDF 등록 및 geospatial 데이터 조회
· 마무리
wget https://github.com/Esri/gis-tools-for-hadoop/archive/master.zip
unzip master.zip
hadoop fs -mkdir /user/hive/demo
hadoop fs -put gis-tools-for-hadoop-master/samples/data/counties-data /user/hive/demo
hadoop fs -put gis-tools-for-hadoop-master/samples/data/earthquake-data /user/hive/demo

add jar /home/hadoop/esri-geometry-api-2.2.3.jar /home/hadoop/spatial-sdk-hive-2.1.1.jar /home/hadoop/spatial-sdk-json-2.1.1.jar;
CREATE FUNCTION ST_Point AS 'com.esri.hadoop.hive.ST_Point';
CREATE FUNCTION ST_Point AS 'com.esri.hadoop.hive.ST_Contains';

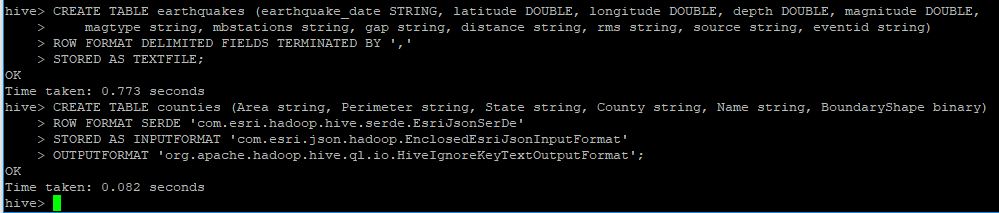
CREATE TABLE earthquakes (earthquake_date STRING, latitude DOUBLE, longitude DOUBLE, depth DOUBLE, magnitude DOUBLE,
magtype string, mbstations string, gap string, distance string, rms string, source string, eventid string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
CREATE TABLE counties (Area string, Perimeter string, State string, County string, Name string, BoundaryShape binary)
ROW FORMAT SERDE 'com.esri.hadoop.hive.serde.EsriJsonSerDe'
STORED AS INPUTFORMAT 'com.esri.json.hadoop.EnclosedEsriJsonInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat';
LOAD DATA INPATH '/user/hive/demo/earthquake-data/earthquakes.csv' OVERWRITE INTO TABLE earthquakes;
LOAD DATA INPATH '/user/hive/demo/counties-data/california-counties.json' OVERWRITE INTO TABLE counties;

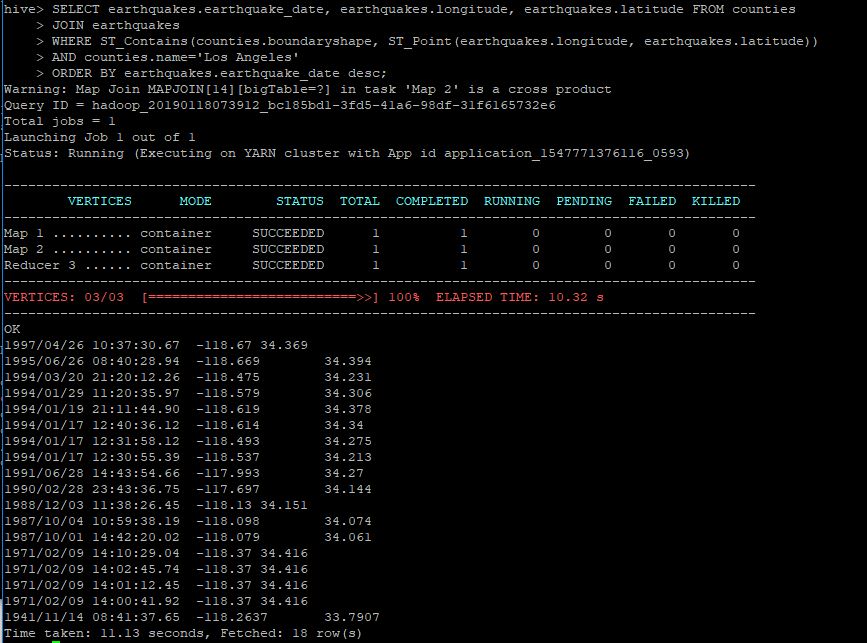
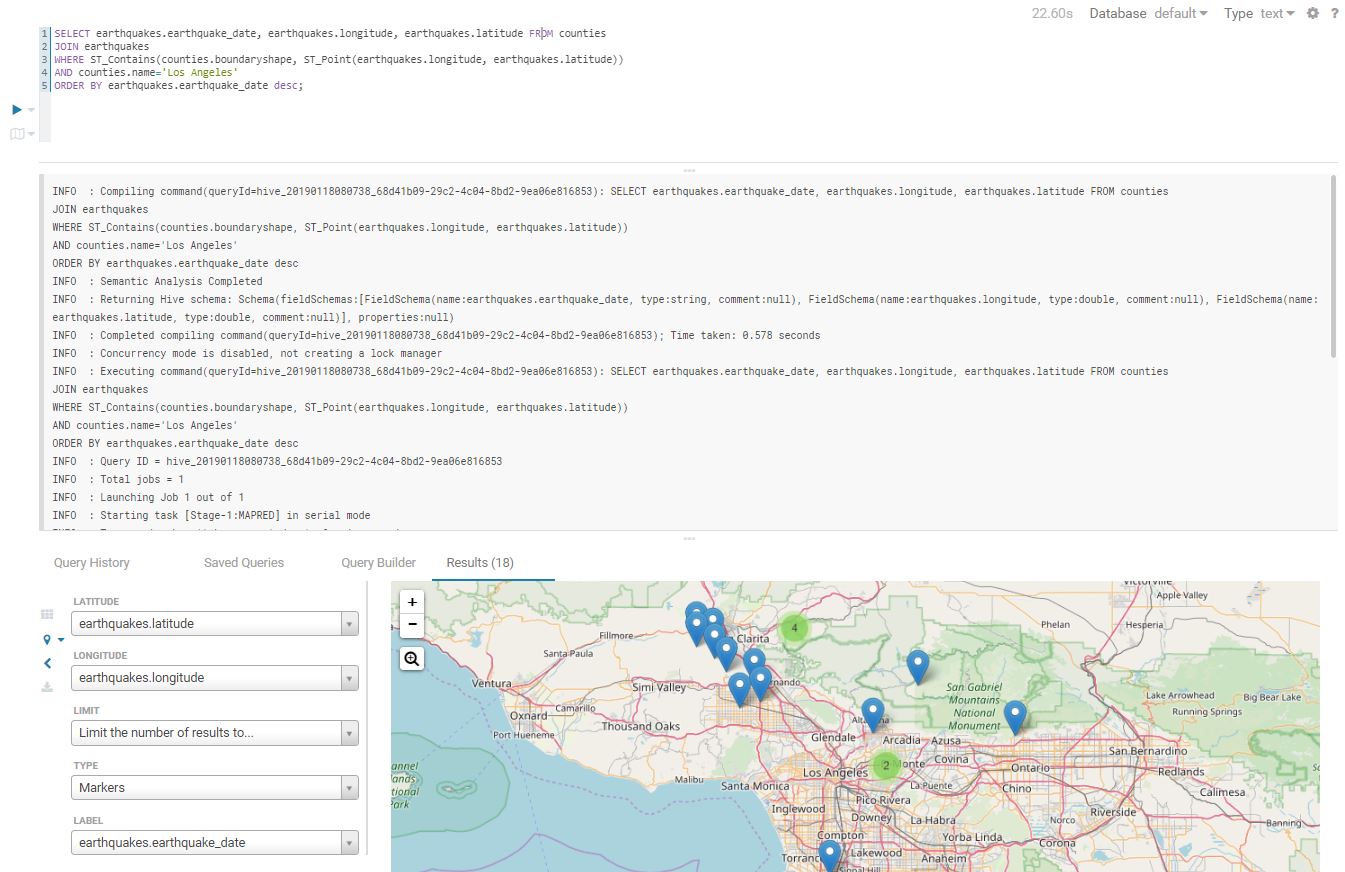
SELECT earthquakes.earthquake_date, earthquakes.longitude, earthquakes.latitude FROM counties
JOIN earthquakes
WHERE ST_Contains(counties.boundaryshape, ST_Point(earthquakes.longitude, earthquakes.latitude))
AND counties.name='Los Angeles'
ORDER BY earthquakes.earthquake_date desc;